Introduction
Knowledge of Latin grammar and morphology is often acquired before a wide vocabulary. Thus, even a moderately advanced Latin student may find himself forced to rely heavily on a dictionary when reading an unglossed passage. The process of frequently consulting a physical dictionary is very time-consuming, fractures the student’s concentration on the overall sense of the passage, and generally makes the whole process of reading Latin quite tiresome. The time required to interpret unknown words could be greatly reduced by using an electronic dictionary tool rather than a paper dictionary, but such dictionary programs are non-trivial to construct since they must take account of the Latin inflection system in order to retrieve possible headwords for a given declined form.
Some programs which can perform this analysis, such as William Whitaker’s Words and the Perseus Word Study tool, are not optimized for reading whole passages with many unknown words. Other tools which are designed for long passages, such as Collatinus and NoDictionaries, do not appear to have the ability to present parsing information. The Alpheios reader works well for extended passages and displays parsing information, but by using a server API for morphological analysis, it introduces delays in fetching results, which negatively impacts the reading experience.
In this report, I will briefly describe the implementation, features, and user reception of my “Vocabulator”, which is a web application especially designed to aid intermediate to advanced Latin students in reading unglossed passages with high densities of unknown words. It is cross-platform, runs offline in a web-browser, and can export a customizable vocabulary list for any section of Latin text. The application stores user data such as a list of known words persistently on the user’s computer. The dictionary data was taken from the William Whitaker’s Words project.
Morphological Analysis
At the core of the program is the morphological analyzer, which transforms a declined (or "surface") word form into a list of possible stems. The dictionary is then searched for these stems, and any matches are returned.
The algorithm for reducing surface forms to stems can be visualized as a process of working backwards through a directed graph representing the Latin declension system. Nodes in the graph correspond to particular named forms (e.g., “2nd person singular present passive indicative 1st conjugation regular verb” or “[stem] present 1st conjugation regular verb” or “ablative fem singular 2nd declension positive adjective”) and links in the graph correspond to operations transforming one named form to another (e.g, “append -amus”, or “append -ibus”). The diagram below should help visualize this process:

In general, each operation which takes a stem and generates a declined form has an associated inverse operation which takes a declined form and reduces it back to a stem. To find possible stems for a given declined form, these reduction operations are applied on the word in sucession. Each successful application of an reduction operation “moves” the word back one link through the directed graph. Eventually the modified word will "arrive" at one or more stem nodes. The dictionary is then searched for the form at these stem nodes. The reduction process is visualized in the diagram below:

Note that not all candidate stems produced by this algorithm correspond to real words. For instance, the input form “porto” would reduce to these candidate stems:
- “port-” (1st conjugation present verb stem)
- “port-” (2nd declension positive adjective stem)
- “port-” (2nd declension masculine noun stem)
- ... and more (gerunds, participles, etc.)
Although most Latin words can be handled by this simple suffix stripping algorithm, some words require significantly more complicated processing. For instance "portarequene" can be parsed not only as an infinitive but also as various syncopated forms:

To parse "portarequene" as a syncopated perfect, the lemmatizer follows steps basically like these:
- Remove -ne
- Remove -que
- The form is now "portare".
- The syncopation reduction/inversion rule iterates through
all the non-final vowels and tries expanding them as if they were the result of syncopation.
This will result in several new forms to be reduced, most of which are discarded
because they reduce to stems which are not in the dictionary.
The full set of productions is:- portare → portavire
- portare → portavere
- portare → portavre
- portare → povirtare
- portare → povertare
- portare → povrtare
- Among the other forms produced, "portavere" is run through another de-syncopation inversion/reduction rule, which expands the final "-ere" to "-erunt"
- "portaverunt" is then reduced to the perfect stem "portav-" using simple suffix removal.
- To confirm the syncopation was valid (and not a replacement in the middle of a word), the final found stem ("portav-") is checked to end with a "v".
- The results shown to the user explain the process used to derive the input form (portareque) from the expanded form (portaverunt). (See the image above)
Each of the reduction rules in Vocabulator is implemented as a JavaScript function which is fed into a general-purpose lemmatization engine. These rule functions (whether they represent simple suffix removal or something more complicated as in syncopation) are black-boxes to this engine, and thus the engine can theoretically be used to lemmatize a wide variety of inflected languages simply by providing a new collection of rewriting rules. For a detailed description of this abstract lemmatization engine, see the comments in the source code.
User Interface
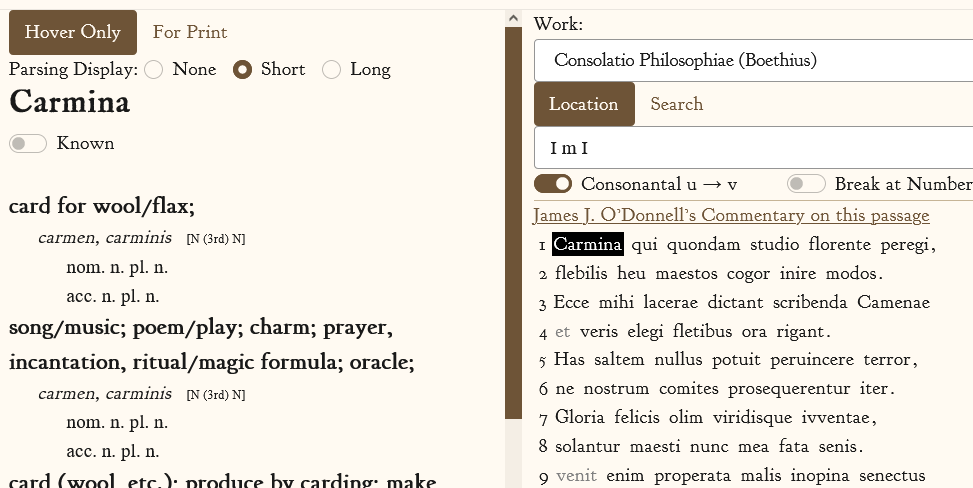
The main screen is vertically split into two panels: one containing the text on the right, and one containing vocabulary output on the left.

The text can be supplied either by pasting into a textbox, or by entering a passage reference for a preloaded work, in this case the Consolatio.
Vocabulator runs entirely in the browser, and unlike many other tools (such as the Alpheios reader) it does not rely on a server API for morphological analysis. Even for complicated words like "portarequene" which result in over 1000 analysed forms, processing only takes around 30ms. This is fast enough to allow results to be shown immediately when hovering over words, without precomputing or caching results.
Words can be control-clicked to be marked as known. Known words are shown in gray and will not be included in printed vocabulary lists. A user's list of known words is saved in browser localStorage.
The
user can also view a complete listing of all possible definitions for
all unknown words in a passage (without parsings) by switching to the
“For Print” mode using the buttons at the top of the left
panel.
 The “For Print” mode also allows easily printing
this customized vocabulary list, for instance to be used when
translating in the classroom.
The “For Print” mode also allows easily printing
this customized vocabulary list, for instance to be used when
translating in the classroom.
Student Experiences
After developing the program for my own use and the use of other students in my upper-level Boethius class, the program was given to students in an intermediate Latin class. The students were optionally allowed to use the program to prepare passages ahead of time for translation in class, and to export a vocabulary list to aid them with their in-class translation. While a formal survey of the students’ experiences with the program was not conducted, the overall response seemed to be very positive. Students found that using Vocabulator greatly reduced the time they spent preparing translations and made the classwork significantly easier. Several students, however, seemed to not be aware of the ability to remove words from the produced vocabulary lists by marking words as known. Although this feature is explained in the help page for Vocabulator, an improved version of the tool should perhaps call attention to this feature more prominently, since it saves paper and reduces time spent filtering through already known words when trying to use a vocabulary list in class.
Conclusion
Vocabulator seems to present a novel approach to helping Latin students read unglossed texts. It is designed especially for reading extended passages and gives full parsing information. By performing all word analysis in the browser, it provides a smooth and interactive reading experience. It integrates well with traditional classroom instruction by allowing a personalized vocabulary list to be exported for any passage. Vocabulator could be extended to other languages, such as Greek or Hebrew, by reusing the engine component (which has no direct connection to Latin), and replacing the Latin rules and dictionary.