Introduction
Knowledge of Greek grammar and morphology is often acquired before a wide vocabulary. Thus, even a moderately advanced Greek student may be forced to rely heavily on a dictionary when reading an unglossed passage. The process of frequently consulting a physical dictionary is very time-consuming, fractures the student’s concentration on the overall sense of the passage, and generally makes the whole process of reading Greek quite tiresome. The time required to interpret unknown words could be greatly reduced by using an electronic dictionary tool rather than a paper dictionary, but such dictionary programs are non-trivial to construct since they must take account of the Greek inflection system in order to retrieve possible headwords for a given declined form.
Some programs which can perform this analysis, such as the Perseus Word Study tool, are not optimized for reading whole passages with many unknown words. The Alpheios reader works well for extended passages and displays parsing information, but by using a server API for morphological analysis, it introduces delays in fetching results, which negatively impacts the reading experience.
In this report, I will briefly describe the implementation and features of my “Greek Vocabulator”, which is a web application especially designed to aid intermediate to advanced Greek students in reading unglossed passages with high densities of unknown words. It is cross-platform, runs offline in a web-browser, and can export a customizable vocabulary list for any section of Greek text. The application stores user data such as a list of known words persistently on the user’s computer. Internally, the morphological analysis is done by the Perseus project's Morpheus engine, and the dictionary is from the Alpheios project.
Background
Reading unglossed Latin passages presents a similar difficulty for intermediate students. In a previous project, my Latin Vocabulator, I created a web application especially designed to aid intermediate to advanced Latin students in reading unglossed passages with high densities of unknown words. By performing all morphological analysis on-the-fly directly within a user's browser, the Vocabulator was able to be significantly more interactive than the Perseus Word Study Tool or Alpheios reader, which rely on a server API for morphological analysis. Student feedback on the Vocabulator was very positive, and they found it significantly reduced the time they spent preparing translations for an intermediate Latin class.
The semester after I created the Vocabulator for my own use in an upper-level Boethius class, I started studying Attic Greek. I soon found myself wishing for a Greek version of Vocabulator. I especially missed the interactivity and fluidity of reading provided by the very fast client-side morphological analysis in Vocabulator.
First Attempts
At first glance, it seemed I had only a few options if I wanted to create a web application for reading Greek with interactivity similar to Vocabulator:
- Create or find a morphological analysis engine for Greek which is written in Javascript and can thus be run in the browser
- Set up a server which would use a non-Javascript engine (such as Morpheus) to pre-analyze all the words in a passage at the start of a reading session and send the results back to the browser. The client-side application would then be able to display analyses to the user very quickly, because it would have the analyses for every word in the passage already cached.
Although the latter option might seem to be the obvious choice, I decided against it for several reasons. For one thing, it makes impossible some neat features of my Latin Vocabulator such as offline use. It also adds significant complexity to the hosting of the application, while my Latin Vocabulator can be hosted from anywhere that can serve static files.
So I was left with the first option of using a Greek morphological analysis engine written entirely in Javascript. As far as I'm aware, no such engine exists. In fact, I don't know of any Greek morphological analyzer besides the Perseus project's Morpheus engine, and Morpheus is written in C. Undeterred, I set about writing my own engine in Javascript/Typescript.
While I had been able to implement a basic analyzer for Latin in about a weekend for my Latin Vocabulator, creating a Greek engine turned out to be far more difficult than I had anticipated. I had at this point only completed two semesters of Greek, while at the time I created my Latin Vocabulator I had studied Latin all through high school and one semester already in college. But on top of that, Greek morphology is just more complicated than Latin.
To try to speed things up, I investigated reusing the Morpheus engine's declension tables but writing my own engine to work with the tables. But after seeing how complicated the internals of Morpheus were, I decided that this route wasn't tractable either.
The Solution: Emscripten
At this point, I wondered if I had an unsolvable problem. I wanted to have everything run in the browser, but I wouldn't write my own engine and the only engine available is Morpheus, which is written in C, not Javascript. And indeed this would be impossible, except for one thing: programs written in C can actually be run in the browser!
But how, you ask? Through an amazing project called Emscripten, C and C++ programs can be compiled to WebAssembly binaries and run in the browser. Command line arguments, stdin/stdout, virtual filesystems, etc. can all be supplied by Javascript, allowing the C program to run almost exactly the same as it runs in a standard desktop environment, with very few changes to the C source code.
I started looking at getting Morpheus to compile under Emscripten so I could have the completeness and accuracy of the Morpheus analyzer in my Greek Vocabulator without having to host a morphological analysis API server. There were a few difficulties to get through, but overall it wasn't actually very difficult to get Emscripten to compile Morpheus for the web. I only had to make a few minor changes to the Morpheus source code, and most of those were just to make Morpheus be in better compliance with the C standard.
After I compiled Morpheus to a web assembly binary and the stem files and declension tables packaged into a format that could be loaded by the Emscripten runtime as a virtual file system accessible by the Morpheus web assembly binary, the rest of the steps to make the Greek Vocabulator were fairly straightforward. I wrote some Javascript code using async/await to wrap the Morpheus command-line “cruncher” interface into a function that could be called by the rest of my code. Morpheus by itself only returns analyses, not definitions, so I still needed a dictionary. Luckily, I found that the Alpheios project had published their Major + Middle Liddell Greek dictionary in an easy to process format, and I was able to reuse that with some minor modifications.
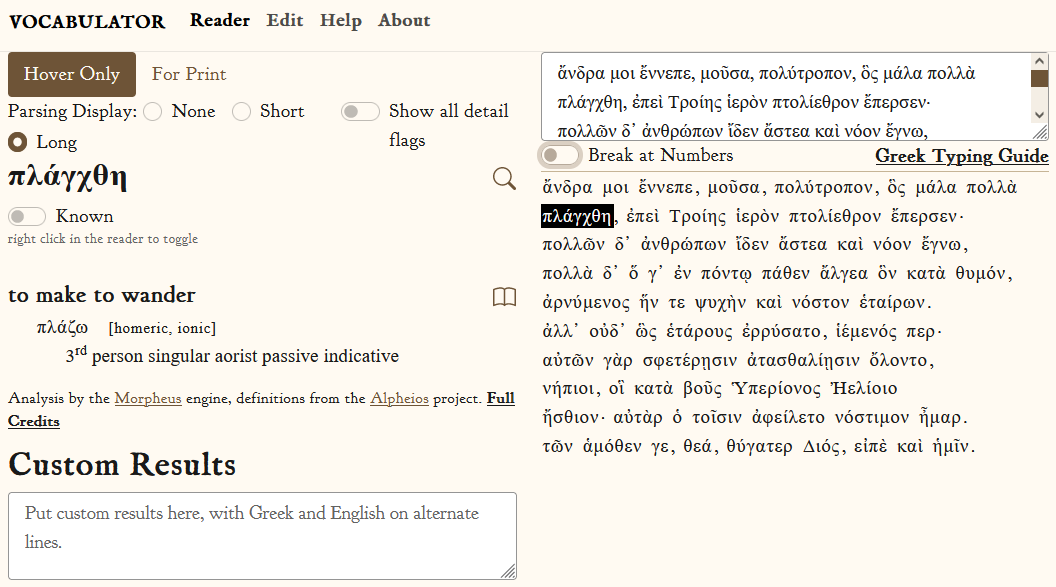
User Interface
The user interface of the finished Greek Vocabulator is very similar to that of the Latin Vocabulator. The main screen is vertically split into two panels: one containing the text on the right, and one containing vocabulary output on the left.

The text can be supplied either by pasting into a textbox, or by typing in the Greek manually. The Greek entry box is programmed to allow users to type Betacode and see rendered Greek unicode appear. It should hopefully be easier for beginning Greek students to learn to use this format rather than installing a Greek keyboard pack. A virtual Betacode reference sheet is shown when clicking on "Greek Typing Guide".

When the user hovers over the word, analysis results are shown in the panel on the left. The book icons to the right of a result are direct links to the LSJ entry for the result, and the search icon at the top of the results panel is a direct link to the Perseus Word Study Tool page for the hovered word. These quick links are useful when a more nuanced understanding of the word is desired or Vocabulator fails to produce results.

Words can be control-clicked to be marked as known. Known words are shown in gray and will not be included in printed vocabulary lists. A user's list of known words is saved in browser localStorage.
The user can also view a complete listing of all possible definitions for
all unknown words in a passage (without parsings) by switching to the
“For Print” mode using the buttons at the top of the left
panel.
 The “For Print” mode also allows easily printing
this customized vocabulary list, for instance to be used when
translating in the classroom.
The “For Print” mode also allows easily printing
this customized vocabulary list, for instance to be used when
translating in the classroom.
Conclusion
As described above, the Greek Vocabulator runs entirely in the browser, and unlike many other tools (such as the Alpheios reader) it does not rely on a server API for morphological analysis. The Morpheus engine is very fast, and so analysis results can be computed on the fly and still shown almost immediately after a user hovers over a word, without needing to pre-analyse all the words in a passage. This also allows the entire application to be downloaded and used without an internet connection.
Greek Vocabulator seems to present a novel approach to helping Greek students read unglossed texts. It is designed especially for reading extended passages and gives full parsing information. By performing all word analysis in the browser, it provides a smooth and interactive reading experience. It integrates well with traditional classroom instruction by allowing a personalized vocabulary list to be exported for any passage.
Because the Morpheus engine supports Latin and Italian as well as Greek, this version of Vocabulator could be extended to these other languages without much trouble, provided a good machine readable dictionary could be found. More broadly, the use of Emscripten to transform previously command-line or desktop only applications for the web presents exciting new opportunities for making the existing body of advanced digital humanities tools more interactive and accessible.